

Introduction
Electronic health records (EHRs), also known as electronic medical records (EMRs), have been established as a means of improving accessibility, availability, and legibility of patient history and information.1 There has been an increase in the use of electronic data capture (EDC) software for storing subject data collected in clinical trials that is parallel to the increased use of EHRs in healthcare.2 A shift towards EDC has been substantiated by increased efficiency, improved data integrity, and decreased data collection costs.3,4
For many years, clinical trial sponsors have focused on the promise of EHR-to-EDC integration as a means to improve the quality and timeliness of data in the EDC system. For example, TransCelerate’s eSource initiative promotes the acceleration of implementing EHR-to-EDC integrations in clinical research (CR) trials globally.5
Despite the assurance that EHRs would improve the safety and quality of care, there is growing evidence to suggest that EHR-related errors result in data that is inaccurate, cluttered, redundant, and/or irrelevant.6 This is unsurprising, given that EHRs were originally developed by insurers to review payment strategies for billing purposes. Documentation of patient encounters therefore focuses more on generating the correct billing codes based on the procedures performed and the amount of information entered than on the accuracy of information not related to billing, such as the medical history and medication history.7 However, crucial areas of data in the EHR are referenced when screening subjects into clinical research trials. These include common areas of inaccuracy in the EHR, such as patients’ current medications and medical history.1 These data are often used to determine subject eligibility, or to stratify subjects into discrete cohorts for analysis. However, as there is no current regulatory system in place to monitor the safety and accuracy of the data, EHRs do not have true interoperability.6 As such, some observers believe that EHR systems in their current state cannot effectively and safely serve patient care.8,9
In clinical research, the Principal Investigator (PI) is responsible for conducting the trial, including the collection of reliable data. They are therefore responsible for ensuring the veracity and quality of the data in the EDC.10 In this study, we will argue that, given the risk of EHR errata and redundancy, direct PI review, interpretation, and calibration of the EHR data on current medications and medical history is crucial prior to the data entry into the EDC. Thus, direct EHR to EDC integration without PI intermediation could result in lower quality and reliability of data with increased risks to patient safety through inaccurate eligibility determination.
The purpose of this paper is to showcase the fallacy of the assumptions that direct EHR to EDC data entry are error-free or appropriate for use. In this retrospective study, we focused on two elements in the EHR that are foundational to determining subject eligibility for clinical research trials: medical problem lists and medication history. We measured concordance between the subject’s EHRs at time of screening and the data entered into the EDC for the screening visit, in order to assess how accurate and reliable the EHR data was as a basis for clinical trial data entry. This presumes that the EDC data is the true data and that the EHR is the variable.
Methods
We solicited five US-based clinical research sites that were conducting active clinical trials. Table 1 provides descriptive statistics about the sites. Given that the collection of data was retrospective and was covered by the informed consent form that subjects signed prior to enrollment, sites were expected to comply with applicable legal requirements and to obtain additional sponsor or subject clearance as needed. The sites solicited all utilize the CRIO eSource platform, an electronic records system that permits sites to configure source templates and to capture source data. Site selection was conducted by an email survey. All active research sites that were currently using the CRIO software were sent an email that requested their participation in this study. All sites that responded in the affirmative were selected and their data collected. This data collection method establishes the foundational data for each subject as it pertains to that clinical trial. Sites then use this records system for subsequent entry into the EDC system. Given that EDC data is expected to be extracted directly from source data to retain data integrity, we will assume data ultimately entered into the EDC is identical to data in the CRIO eSource platform. Table 1 provides a description of the research sites, including years in practice, therapeutic specialties, staff size, and the number of active studies in CRIO.
Description of Research Sites.
| Years in Practice | Therapeutic Specialties | Staff Size | Active Studies in CRIO | |
| Site 1 | 12 | Multi-therapeutic including Narcolepsy, COPD, Asthma, Obstructive Sleep Apnea, Bronchiectasis | 7 total staff including 3 investigators | 19 |
| Site 2 | 8 | Multi-therapeutic including Fatty Liver Disease, Migraine, Hot Flashes, Birth Control Pills, Alzheimer’s Disease | 14 total staff including 2 investigators | 34 |
| Site 3 | 28 | Multi-therapeutic including Psoriatic Arthritis, Rheumatoid Arthritis, Osteoarthritis, Vaccines | 8 total staff including 4 investigators | 16 |
| Site 4 | 27 | Fatty Liver/NASH | 19 total staff | 10 |
| Site 5 | 22 | Endocrinology and Metabolic Diseases | 4 total staff including 1 investigator | 12 |
Participating clinical research sites submitted EHR data for 70 subjects. Three sites provided 20 subjects each, and two sites provided 5 subjects each. All subjects had been screened and consented into various trials between January 1, 2020 and December 31, 2021 at the solicited sites. Subjects were included provided that, in the course of a subject’s screening, the CR site had obtained an up-to-date medical record (eg, medical progress notes, patient portal documentation) that included medical problems and medication history. Medical history must have been documented in either CRIO eSource or, for visits completed outside the system, in uploaded copies of paper source.
The subjects’ medication history and medical problem list were extracted and reviewed. For each subject, we printed out their screening visit eSource data and EHR data from CRIO to present as paired documents to the medical reviewer, who was a family medicine nurse practitioner. To ensure confidentiality of the subjects, site staff redacted any private health information (PHI) within the EHR dataset before submission to the medical reviewer. Additionally, the eSource data utilized in this study only referred to subjects by the subject ID assigned by the site during enrollment.
Given that the source data is considered the “source of objective truth” for clinical trials, we assumed that the eSource served as the true record in our comparisons of EHR versus eSource. Records were therefore deemed incomplete, irrelevant, and/or inaccurate when comparing EHR to eSource. The medical reviewer analyzed each medication and each medical problem in the EHR and denoted them as “in source” (indicating complete conformity between EHR and eSource), “not in source”, or “modified to source” (indicating modification of any kind between the EHR and eSource). Next, the medical reviewer analyzed the eSource medication list for that subject’s screening visit to find medications and medical problems that were “not in EHR”.
Finally, the medical reviewer categorized each record as “concordant”, “incomplete”, “irrelevant”, or “inaccurate”. The medical reviewer was educated about the research agenda and was trained in discerning the criteria as defined below. After the medical reviewer completed their review, the physician supervisor evaluated and revised the categorizations as needed to ensure validity. Agreement between the two reviewers was required before mapping of the data could proceed. A summary of the definitions used by the medical reviewer and physician supervisor is provided in Table 2.
Definitions of Categories Used by Medical Reviewer and Physician Supervisor.
| Category | Definition |
| Concordant | Present in both EHR and eSource (Medication or Medical Problem) |
| Incomplete | Not present in EHR. Present in eSource (Medication or Medical Problem) |
| Irrelevant | Present in EHR. Not present in eSource (Medication or Medical Problem) |
| Inaccurate | Present in both EHR and eSource, but incorrect information in the EHR compared with the eSource (Medication or Medical Problem) |
| Allowed Records | Medical problem that was modified in source but still concordant |
| Consolidation | Mapping multiple medical problems in the EHR into one problem in the eSource |
| Disintegration | Mapping a single medical problem in the EHR to multiple problems in the eSource |
| Term Modification | Mapping a medical problem in the EHR to a problem in the eSource that was worded differently with the same meaning. |
Medication History
Upon comparing medication history records in the EHR and eSource, the medical reviewer categorized each record as concordant, incomplete, irrelevant, or inaccurate. A concordant record was a medication that was listed in both the EHR and eSource. Under the discretion of the medical reviewer, concordant records included records that were deemed “modified to source” as long as the medication was listed in the same dosage, formulation, and start/end date. Spelling errors and conversions of medication names (eg, from brand name to generics or vice versa) were denoted as “modified in source” but not considered discordant. The definition used for an incomplete record was a single medication not listed in the EHR that was listed in the eSource. An irrelevant record was a single medication listed in the EHR that was not listed in the eSource and so was deemed immaterial for the trial (eg, the medication listed was a duplicate, the subject did not report taking the medication at screening, or the medication was completely irrelevant to study parameters). Finally, the definition used for an inaccurate record was one that included errors that compromised the veracity of data (eg, incorrect dosing, start/end date).
Medical Problem Lists
The definitions of incompleteness, irrelevancy, and inaccuracy utilized in the analysis of the medication history were similarly applied in the analysis of medical problem lists. An incomplete medical problem record was a single problem (including symptoms, conditions, disease, diagnosis, etc.) not listed in the EHR that was listed in the eSource. An irrelevant record was a single problem listed in the EHR that was not listed in the eSource and was deemed immaterial for the trial. An inaccurate record was one that included errors that compromised the veracity of data (eg, number of years since the subject was first diagnosed with a condition). When comparing problems that were pulled from EHR to eSource verbatim, the medical reviewer did not count spelling errors as inaccuracies.
Similar to medication records, a concordant problem record was one that was listed accurately in both EHR and eSource. However, concordant problem records were classified further to account for mappability of concordant problem records that were deemed “modified in source”. For those terms that were not verbatim transferred from EHR to eSource, we had to consider how much concordance there was between EHR and eSource data after investigator interpretation. If there was not a word-for-word match between a problem in the EHR and the associated eSource, the medical reviewer allowed for consolidation, disintegration, and term modification of problems to still be deemed concordant, collectively referred to as allowed records.
The definition of an incomplete record stipulated that the absent information was critical in providing full context on the subject’s illness or on the nature of the disease. Pursuant to that, the medical reviewer allowed for non-verbatim mismatches in problems between EHR and their corresponding eSource records as long as the problems reliably mapped to each other. As an example of consolidation, the presence of “coughing” and “runny nose” in an EHR problem list were not considered irrelevant if they were left out of the eSource as long as those two symptoms collectively map to a single consolidated problem, such as “common cold”, in the eSource. Similarly, as an example of allowing for disintegration, the problem “GERD” in the EHR was considered equivalent to the combination of problems “acid reflux” and “regurgitation of food” in eSource. Finally, another consideration of mappability was that of term modification. Two equivalent problems which were worded differently between EHR and eSource were not counted as inaccurate (eg, “chest pain” in EHR and “angina” in eSource data was forgiven). See Table 2 for definitions of the categories used by the Medical Reviewer and Physician Supervisor.
Data Analysis
For medication history, simple descriptive statistics were generated to calculate the percentage of medication records that were accurately recorded as present in both the EHR and the eSource (concordant), not present in the EHR (incompleteness), present in the EHR but not present in source (irrelevancy), and present with substantial modifications (inaccuracy). Simple statistical analyses were also used to calculate the average number of medication records per subject that were concordant, incomplete, irrelevant, and inaccurate.
For medical problem lists, simple descriptive statistics were generated to calculate the percentage of medical problem records in source that were accurately present in both EHR and eSource (concordant), not present in EHR (incompleteness), present in EHR but not in source (irrelevancy), and discordant records (inaccuracy). Simple statistical analyses were used to calculate the average number of medical problem records per subject that were concordant, incomplete, irrelevant, and inaccurate.
For our secondary endpoint, we calculated the percentage of concordant medical problem records that still required mapping as well as the average number of allowed medical problem records per subject. These statistics served as a measure for how much PI intervention, even in concordant EHRs, was required to adjust EHR terminology to study-appropriate terminology.
Results
At the individual record level, 98% of the 1506 total medical problem and medication records were modified in some capacity. This includes all records that were not word-for-word matches between EHR and eSource.
Figure 1 shows the percentage of the total medication records that were modified in source in some capacity. Including concordant records, only 5 records (<1%), of the 764 total medication records were deemed “in source” and not modified in any capacity.
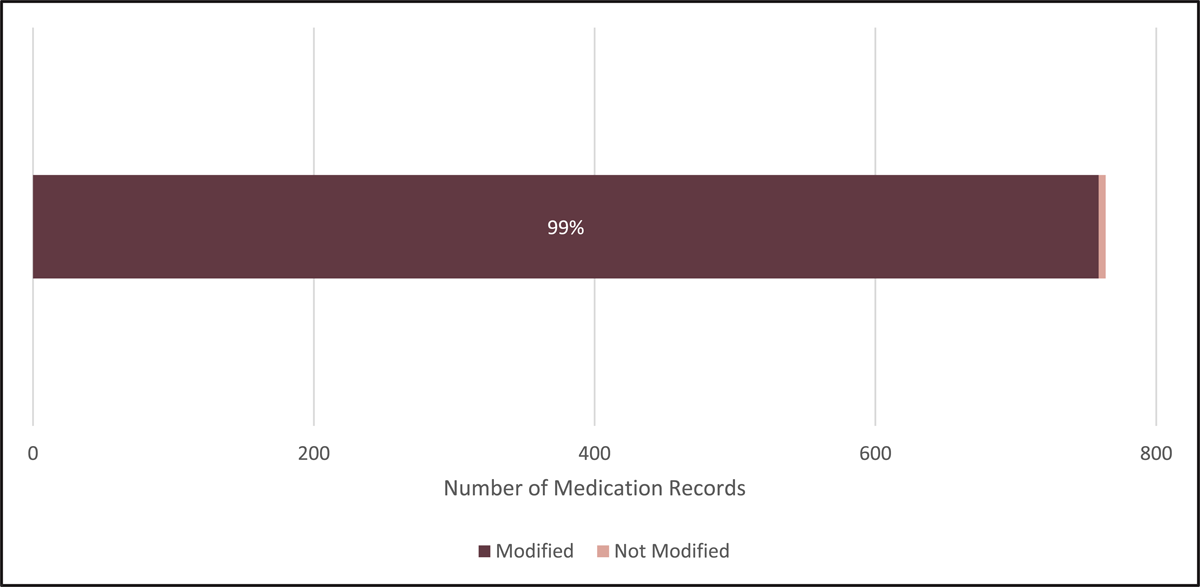
Number of Medication Records Modified to Source vs. Not Modified (In Source).
Figure 2 shows the percentages of the total medication records reviewed that were concordant, incomplete, irrelevant, or inaccurate. Of the 764 total medication records, 239 records (31.3%) were concordant, 289 records (37.8%) were incomplete, 158 records (20.7%) were irrelevant, and 78 records (10.2%) were inaccurate.
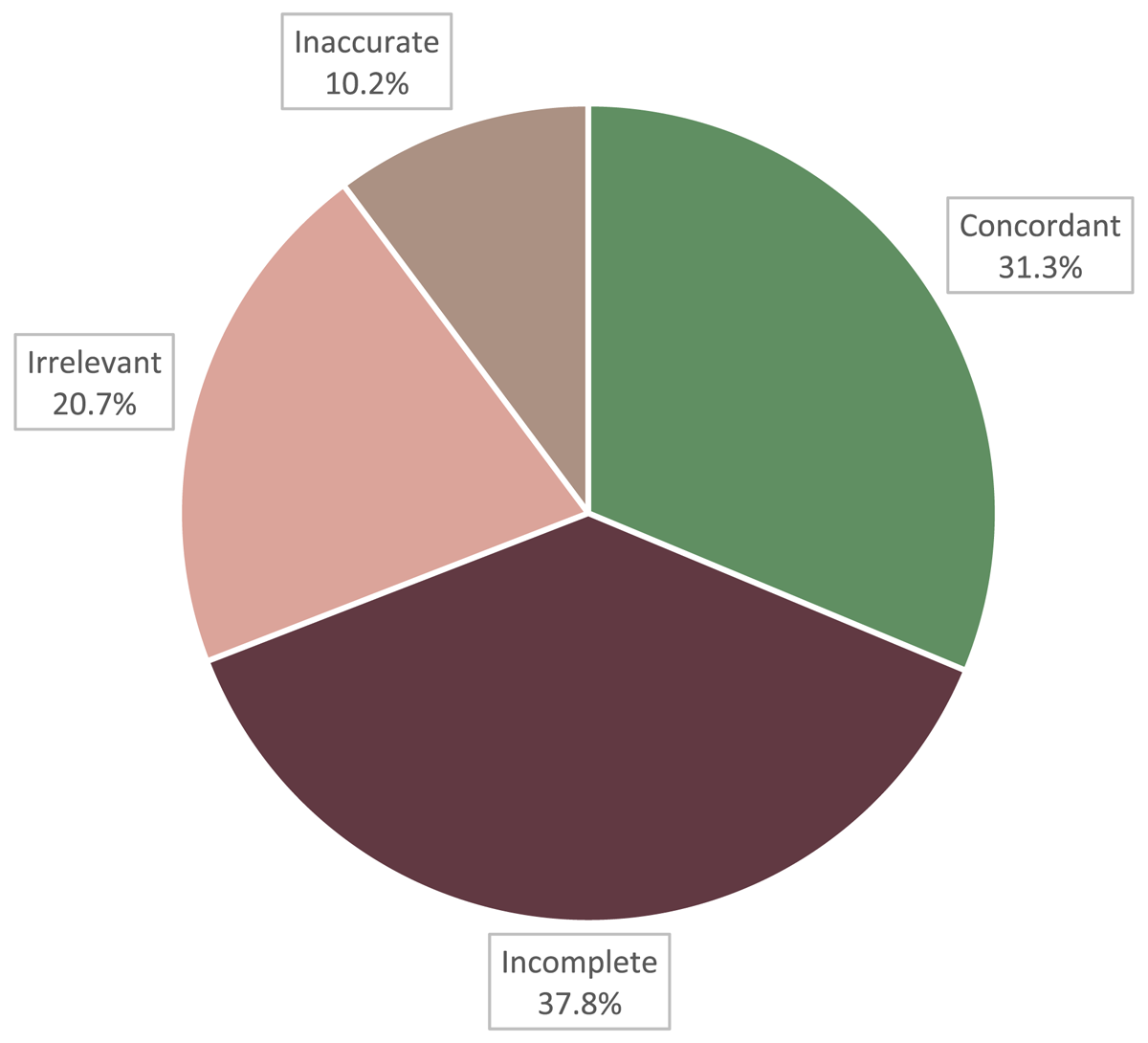
Percentages of Concordant, Incomplete, Irrelevant, and Inaccurate Medication Records.
Figure 3 shows the percentage of the total medical problem records that were modified in source in some capacity. Including concordant records, only 31 records (4%) of the 742 total medical problem records were deemed “in source” and not modified in any capacity.
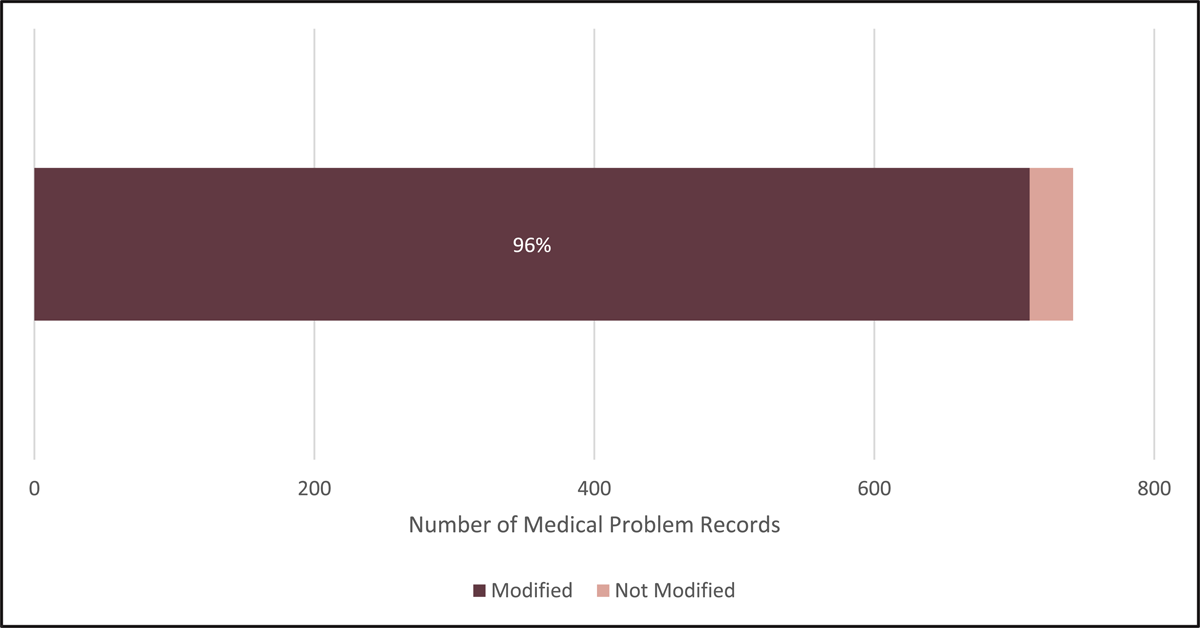
Number of Medical Problem Records Modified to Source vs. Not Modified (In Source).
Figure 4 shows the percentages of the total medical problem records reviewed that were concordant, incomplete, irrelevant, or inaccurate. Of the 742 problem records reviewed, 339 records (45.7%) were concordant, 251 records (33.8%) were incomplete, 148 records (19.9%) were irrelevant, and 4 records (0.5%) were inaccurate.
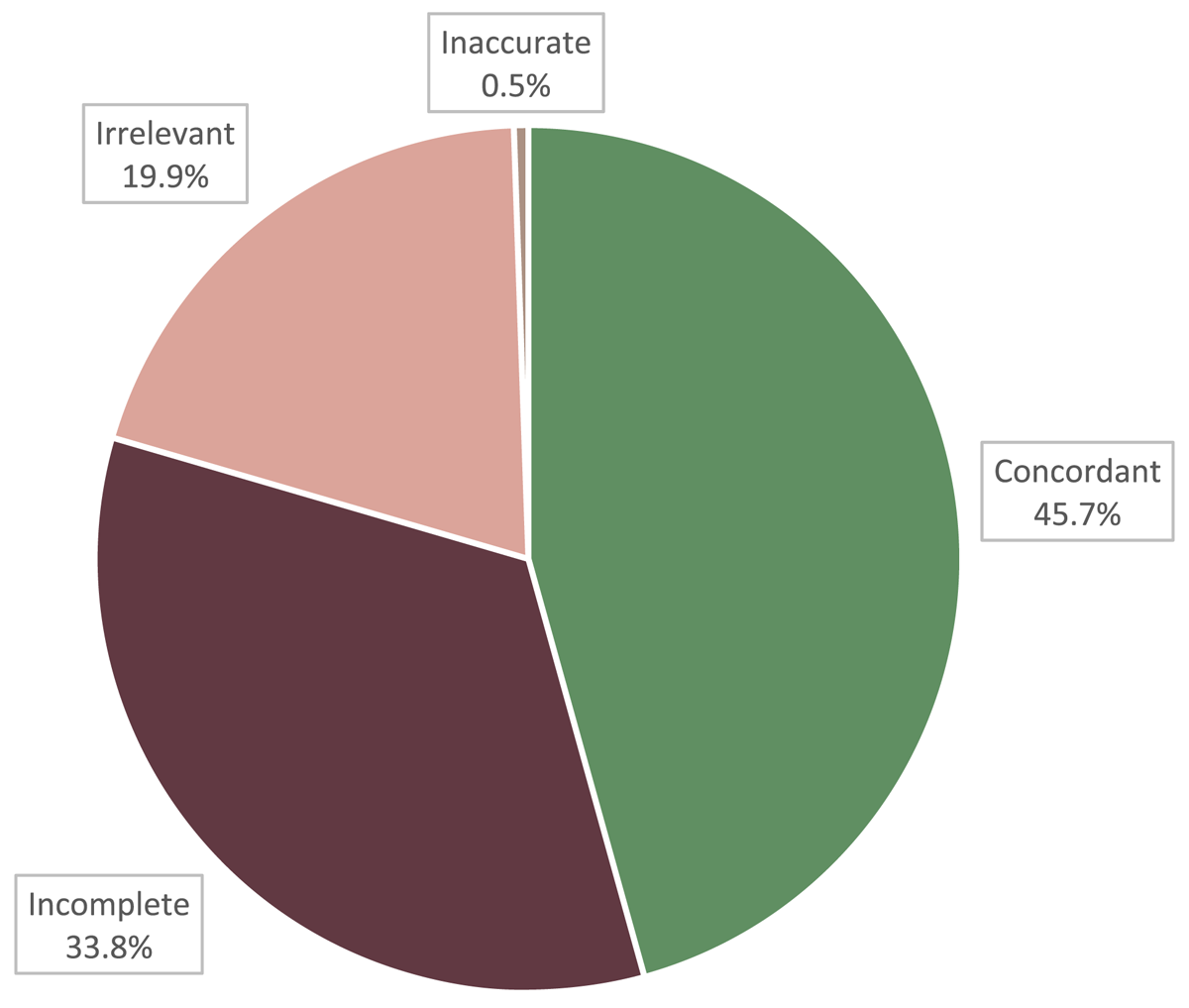
Percentages of Concordant, Incomplete, Irrelevant, and Inaccurate Problem Records.
Table 3 shows the distribution of medications per subject. The average number of medications per subject listed in the eSource was 10.6 whereas the average number of medications per subject listed in the EHR was 6.5. Among all medications listed in the eSource per subject, an average of 3.3 (31.1%) were concordant, 4 (37.7%) were incomplete, 1.1 (10.4%) were inaccurate, and 2.2 (20.8%) were irrelevant.
Average Number of Medications per Subject.
| % of all eSource Medications | ||
| Average Number of Medications in eSource | 10.6 | |
| Average Number of Medications in EHR | 6.5 | 61.3% |
| Average Number of Concordant Medications | 3.3 | 31.1% |
| Average Number of Incomplete Medications | 4 | 37.7% |
| Average Number of Inaccurate Medications | 1.1 | 10.4% |
| Average Number of Irrelevant Medications | 2.2 | 20.8% |
Table 4 shows the distribution of medical problem records per subject. The average number of medical problems listed in the eSource was 10.3 whereas the average number of medical problems listed in the EHR was 6.82. Among all medical problems listed in the eSource, an average of 4.7 (45.6%) were concordant, 3.5 (34.0%) were incomplete, 0.1 (0.01%) were inaccurate, and 2.1 (20.4%) were irrelevant.
Average Number of Medical Problems per Subject.
| % of all eSource Problems | ||
| Average Number of Problems in eSource | 10.3 | |
| Average Number of Problems in EHR | 6.82 | 66.2% |
| Average Number of Concordant Problems | 4.7 | 45.6% |
| Average Number of Incomplete Problems | 3.5 | 34.0% |
| Average Number of Inaccurate Problems | 0.1 | 0.01% |
| Average Number of Irrelevant Problems | 2.1 | 20.4% |
Of the 339 concordant medical problem records, 58 records (17%) were identified as “allowed records”, which indicated that investigator interpretation through mapping was still required. A total of 45.5 hours were spent on the reviews of all records across all 70 subjects: 30.5 hours by the medical reviewer; 15 hours by the physician supervisor. The specific breakdown of time spent on mapping was not calculated but it was reported by the medical reviewer and physician supervisor to have taken more time than other categorizations.
Table 5 shows the total number of allowed records and the distribution of the three types of mapping among the allowed records. Of the 58 allowed records, the majority (56.9%) of mapping was done through term modification while the remaining 43.1% was done through consolidation. Disintegration was not identified in any of the records. The average number of allowed records per subject was 0.82.
Distribution of Allowed Records: Medical Problem Records that Required Mapping.
| Number of Records | Percentage of Allowed Records | |
| Total Allowed Records | 58 | |
| Term Modification | 33 | 56.9% |
| Consolidation | 25 | 43.1% |
| Disintegration | 0 | 0% |
Discussion
In this analysis, we measured concordance between subjects’ EHRs, specifically medication lists and medical problem lists, at the time of screening versus the eSource data, which served as a proxy for data entered into the EDC. The overall abundance of modification between EHR and eSource was notable. Of the medication and medical problem records analyzed, 98% were modified in some capacity (modified from EHR to eSource, not included in eSource, or added to eSource when not present in the EHR). Our definition of modification accounts for any difference between EHR and eSource, including changes to wording that don’t affect the fundamental meaning of the data. This observation (that almost every record was modified) reveals the extensive administrative burden that is present in the data transfer process. This administrative burden of manual data transfer provides an impetus for the development of many new integration systems that streamline data transfer from EDC to EHR by emphasizing a single point of entry that minimizes redundant work. The implementation of these systems has provided evidence that EHR-EDC integration increases efficiency and reduces transcription errors.11,12
However, a breakdown of the nature of modifications between EHR and EDC presented in this study shows that a degree of investigator intervention is necessary and is not completely redundant. Despite the promise of EHRs to decrease the frequency of medical documentation errors,1,6 our results contribute to an increasing body of evidence that details the prevalence of inaccuracy, incompleteness, and irrelevance present in EHR data. Of the 764 medication records reviewed, only 31.3% were concordant while 37.8% were incomplete, 20.7% were irrelevant, and 10.2% were inaccurate. Of the 742 problem records reviewed, only 45.7% were concordant, 33.8% were incomplete, 19.9% were irrelevant, and 0.5% were inaccurate.
The prominent inconsistencies between EHR and eSource can be partially attributed to the inaccuracies of medical and medication histories in the EHR. In terms of medication data, primary care providers are often not promptly alerted of changes to the patient’s medications by other providers, leading to omissions of new medications or to the inclusion of discontinued medications in the EHR.8 These omissions or extraneous inclusions of medications correspond respectively to incomplete and inaccurate medication records in the present study. Similarly, the convenience of copy-paste and templates in EHR systems leads to significant redundancy in which entire sections of clinical notes are carried over to the next note, which can lead to inclusion of outdated information or diagnostic errors in the EHR.9
Notably, even for concordant records in the present study, 17% demonstrated some degree of investigator intervention in parsing through and consolidating related symptoms listed in the EHR into conditions in eSource, disintegrating EHR conditions into separate problem entries in eSource, or modifying terms where appropriate. These decisions, made by investigators when reviewing the EHR and entering data into eSource, are critical in providing a full context of the nature of the subject’s disease(s). This level of investigator interpretation represents the different purposes of clinical data versus research data. Research data often requires a greater level of detail and specificity, for example, the exact dates of medication use. Aligning with the strict definitions delineated in the inclusion and exclusion criteria in research protocols, research data collection is structured and rigorous. In contrast, data for clinical care is tailored to the needs of the patient and is limited to what the clinician deems necessary, whether for the purpose of billing or for care coordination.7
Our results reveal a significant schism between the ideal EHR-EDC integration, in which data could flow directly from EHRs into EDCs, and the practical reality in which intervention is required to audit and interpret EHR data into source data before it is ultimately transferred to EDC. Whether this intervention occurs on the level of research coordinators inputting data, data monitors reviewing data, or investigators ultimately signing off, the responsibility falls on the PI to train staff to identify inaccuracies and to oversee all study data. Until an improved system is developed, whether it involves enhancing EHR accuracy or implementing verification processes in EHR-EDC integration systems, it is crucial that investigators maintain active participation in ensuring the accuracy of source data entry.
Conclusion
Our findings suggest that investigator review and intervention is crucial in parsing out inaccurate and incomplete EHR entries to mitigate the risk of errors being transcribed to EDC. Some limitations of this study include the use of a single platform, which has the potential to introduce bias in the outcome. Regarding the statistical analysis, more detailed statistics could be performed to extrapolate differences in the types of modifications needed that may be distinct between studies in different therapeutic specialties. As this is a descriptive review, no further statistical analysis will be performed. Additionally, there are various staffing structures among research sites in which research coordinators or designated data entry staff perform the majority of the data-auditing prior to data entry. Given the differing workflows and multiple points of data entry, further surveys of sites could be done to identify the primary points of intervention and the associated personnel in the data entry process. This can provide insight into the target audience when implementing improvements in EHR-to-EDC integration systems.
Competing Interests
The authors have no competing interests to declare.
References
1. Hong CJ, Kaur MN, Farrokhyar F, Thoma A. Accuracy and completeness of electronic medical records obtained from referring physicians in a Hamilton, Ontario, plastic surgery practice: A prospective feasibility study. Plast Surg (Oakv). 2015; 23(1): 48–50. DOI: http://doi.org/10.4172/plastic-surgery.1000900
2. Mosa AS, Yoo I, Parker JC. Online electronic data capture and research data repository system for clinical and translational research. Mo Med. 2015; 112(1): 46–52.
3. Pavlović I, Kern T, Miklavcic D. Comparison of paper-based and electronic data collection process in clinical trials: costs simulation study. Contemp Clin Trials. 2009; 30(4): 300–316. DOI: http://doi.org/10.1016/j.cct.2009.03.008
4. Fleischmann R, Decker AM, Kraft A, Mai K, Schmidt S. Mobile electronic versus paper case report forms in clinical trials: a randomized controlled trial. BMC Med Res Methodol. 2017; 17(1): 153. Published 2017 Dec 1. DOI: http://doi.org/10.1186/s12874-017-0429-y
5. Parab AA, Mehta P, Vattikola A, et al. Accelerating the adoption of eSource in clinical research: a Transcelerate point of view. Ther Innov Regul Sci. 2020; 54(5): 1141–1151. DOI: http://doi.org/10.1007/s43441-020-00138-y
6. Bowman S. Impact of electronic health record systems on information integrity: quality and safety implications. Perspect Health Inf Manag. 2013; 10(Fall): 1c. Published 2013 Oct 1.
7. Hersh WR, Weiner MG, Embi PJ, et al. Caveats for the use of operational electronic health record data in comparative effectiveness research. Med Care. 2013; 51(8 Suppl 3): S30–S37. DOI: http://doi.org/10.1097/MLR.0b013e31829b1dbd
8. Kaboli PJ, McClimon BJ, Hoth AB, Barnett MJ. Assessing the accuracy of computerized medication histories. Am J Manag Care. 2004; 10(11 Pt 2): 872–877.
9. Rule A, Bedrick S, Chiang MF, Hribar MR. Length and redundancy of outpatient progress notes across a decade at an academic medical center. JAMA Netw Open. 2021; 4(7): e2115334. DOI: http://doi.org/10.1001/jamanetworkopen.2021.15334
10. Mosa AS, Yoo I, Parker JC. Online electronic data capture and research data repository system for clinical and translational research. Mo Med. 2015; 112(1): 46–52.
11. Thompson M, Len G, Catarina A, Gary P, Jason M. Interface software can markedly reduce time and improve accuracy for clinical trial data transfer from EMR to EDC: The results of two measure of work time studies comparing commercially available clinical data transfer software to current practice manual data transfer. J Clin Oncol. 2022; 40(16): 1573. DOI: http://doi.org/10.1200/JCO.2022.40.16_suppl.1573
12. Murphy EC, Ferris FL, O’Donnell WR. An electronic medical records system for clinical research and the EMR–EDC interface. Invest. Ophthalmol. Vis. Sci. 2007; 48(10): 4383–4389. DOI: http://doi.org/10.1167/iovs.07-0345